Subscriptions¶
This tutorial covers dominoes 4, 5 and 6. There are just two API functions to understand - subscribe and reg-sub - but first let's get an overview.
On Derived Data¶
A UI is just derived data.
A browser renders tree-shaped data called the DOM. Reagent renderers create DOM by computing hiccup-shaped data. Subscriptions deliver data to Reagent renderers. And, app-db is the root of this entire flow.
When Domino 3 (an effect handler) modifies app-db, boom, boom, boom go dominoes 4, 5 & 6,
computing stages of the "materialised view" that is ultimately DOM. Together these three dominoes implement a reactive dataflow.
How Exactly?¶
Data flows through The Signal Graph.
app-db is the ground truth of a re-frame app, and it is at the root of a
Directed Acyclic Graph (DAG) called the Signal Graph. At the other extent of this
graph - at the leaves - are the View Functions, which calculate hiccup.
Typically, the Signal Graph is not deep, with only a few interior layers of nodes
between root and leaves. These interior nodes are the subscription nodes
that you create via reg-sub. Or, more accurately, you use reg-sub to register
how such interior nodes should be created, if and when they are needed.
Data flows through this graph, being transformed by the interior nodes of its journey and, as a result, the data which
arrives at the leaf View Functions will be a materialised view of what was originally in app-db.
The nodes of the graph are pure functions. When data flows along an input arc and into a node,
it becomes "an argument" (an input) to that node's pure function. That function will be "called" with
the input arguments from input arcs, and it will calculate a return value, more data, which then flows along
that node's output arcs to child nodes, where the process repeats. Ultimately, data is delivered into View Functions
via a call to subscribe.
It is derived data all the way through the graph. Even the hiccup produced by leaf nodes is just more derived data. A re-frame app is 75% derived data. I just made that number up, but you get the idea: there's quite a bit of it.
Hell, the process doesn't even stop with leaf View Functions. Hiccup is turned into DOM, which is more derived data.
And the browser turns DOM into pixels on your monitor - yep, more data.
And a monitor turns pixels into photons (data, don't fight me here, I'm on a roll),
which your eye cells detect and turn into chemicals reactions (data) which cause nerve cell signals (totally data),
which reaches the priors in your brain (data). Derived data all the way, baby! Your brain is domino 12.
Too much? Okay, fine. Just the Signal Graph, then.
The Four Layers¶
Conceptually, all nodes in the Signal Graph are a part of the same dataflow, but it is
instructive to label them as follows:
Layer 1- Ground truth - is the root node,app-dbLayer 2- Extractors - subscriptions which extract data directly fromapp-db, but do no further computation.Layer 3- Materialised View - subscriptions which obtain data from other subscriptions (neverapp-dbdirectly), and compute derived data from their inputsLayer 4- View Functions - the leaf nodes which compute hiccup (DOM). Theysubscribeto values calculated by Layer 2 or Layer 3 nodes.
The simplest version of the Signal Graph has no Layer 3 (Materialised View) nodes.
It only has Layer 2 (Extractor) subscriptions which take data from app-db, and those values
then flow unchanged into Layer 4 (View Functions).
In more complex cases, a View Function needs a materialised view
of the data in app-db.
A Layer 2 (extractor) subscription will obtain a data fragment of app-db
which will then flow into a Layer 3 (materialized view) node which will compute
derived data from it and, only then, does data flow into the Layer 4 (View Function)
As Infographic¶
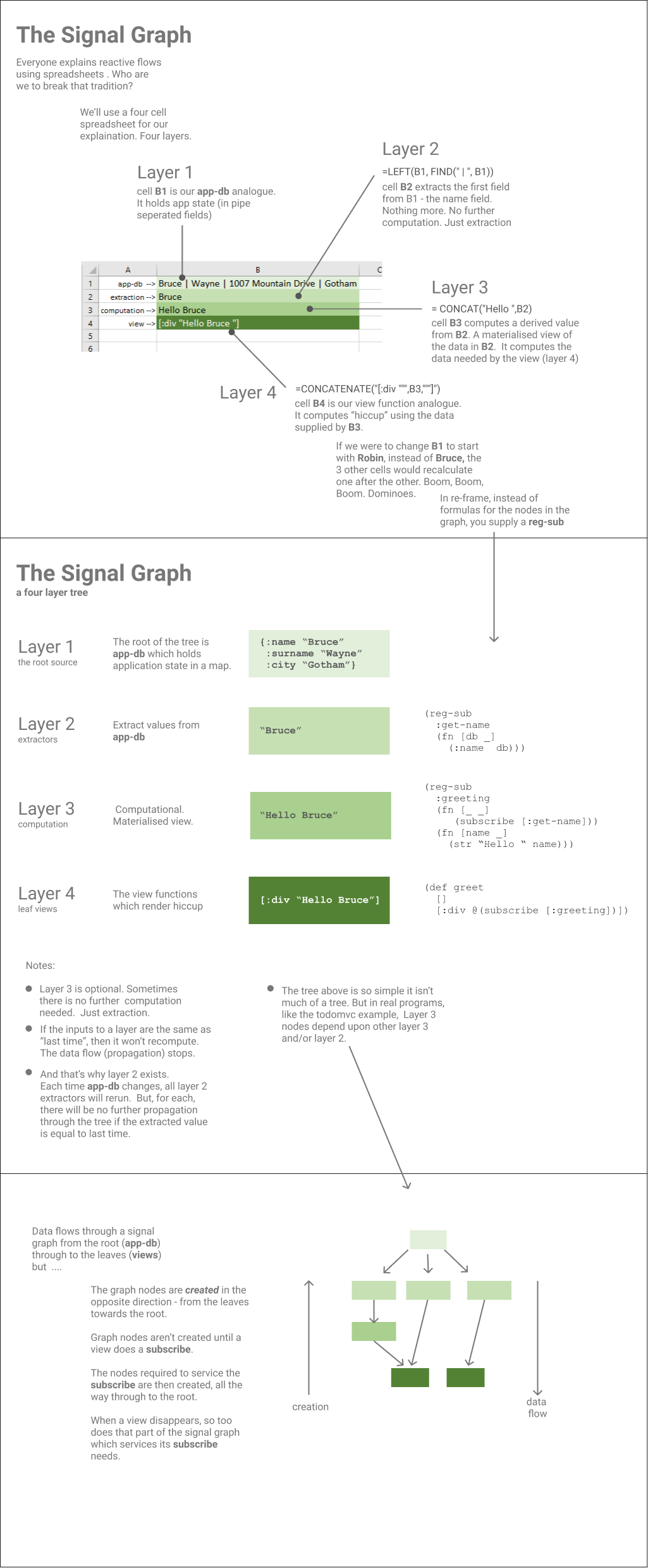
Graph Creation¶
Although data flows through the Signal Graph from app-db towards the
View Functions, graph formation happens in the opposite direction.
When a View Function uses a subscription, like this (subscribe [:something :needed]),
the sub-graph of nodes needed to service
that subscription is created. The necessary sub-graph will "grow backwards" from the View Function
all the way to app-db. So it is "the data-thirsty demands" of currently rendered
View Functions which dictate what nodes exist in the Signal Graph.
And, when a View Function is no longer rendered, the sub-graph needed to service
its needs will be destroyed, unless it is still needed to
service the needs of another, current View Function.
Propagation Pruning¶
The Signal Graph is reactive. When a node's inputs change, the node's subscription handler (function) re-runs automatically. The value it returns then becomes the node's new output value, and it will flow to downstream nodes in the graph, causing them to also re-run.
But this only happens if the handler's output is different to the "last time" it ran. If a handler's return value "this time" is the same as "last time", data is not propagated to the sub-graph. No need. Nothing has changed.
The computation for each node is performed by a pure function and a pure function will return the same value each time it is called with the same arguments. So, if we were to give a downstream node the same inputs as last time, it would produce the same outputs as last time, including the same hiccup at the leaves.
Different How?¶
Data values "this time" and "last time" are regarded as "being the same" if ClojureScript's = says they are.
Why Layer 2 - Extractors?¶
Why is a layer of "extractors" necessary?
It is an efficiency thing. app-db will be changed by almost every event, often in a small,
partial way. But any change whatsoever will cause all Layer2 (extractor) subscription to be automatically re-run.
All of them. Every time. This is because app-db is their input value, and subscriptions re-run when
one of their inputs change.
Extractors obtain a data fragment from app-db and then immediately prune
further propagation of that value if the fragment is the same "last time". As a consequence,
the CPU intensive work in the Layer 3 (materialised view) and Layer 4 (View Functions) is only performed when necessary.
Layer 2 (extractors) act as the Signal Graph's circuit breakers. We want them to be as computationally simple as possible.
reg-sub¶
Subscription handlers are registered using reg-sub. These handlers are the functions which take
input values, flowing into the node, and calculate a derived value to be the node's output.
Extractor subscriptions are registered like this:
(re-frame.core/reg-sub ;; a part of the re-frame API
:id ;; usage: (subscribe [:id])
(fn [db query-v] ;; `db` is the map out of `app-db`
(:something db))) ;; trivial extraction - no computation
This registers a computation function - a pretty simple one which just does an extraction. The argument query-v
is the query vector supplied in the subscription. In our simple case here, we're not using it. But if the subscription was for
(subscribe [:id "blue" :yeah]) then the query-v given to the handler would be [:id "blue" :yeah].
Layer 3 (materialised view) subscriptions depend on other subscriptions for their inputs, and they are registered like this:
(reg-sub
:id
;; signals function
(fn [query-v]
[(subscribe [:a]) (subscribe [:b 2])]) ;; <-- these inputs are provided to the computation function
;; computation function
(fn [[a b] query-v] ;; input values supplied in a vector
(calculate-it a b)))
You supply two functions:
-
a
signals functionwhich returns the input signals for this kind of node. It can return either a single signal, or a vector of signals, or a map where the values are the signals. In the example above, it is returning a 2-vector of signals. -
a
computation functionwhich takes the input values provided by thesignals function, supplied as the first argument, and it produces a new derived value which will be the output of the node.
Registration Doesn't Mean A Node Exists
When you use reg-sub to register a handler, you are not immediately
creating a node in the Signal Graph.
At any one time, only those nodes required to service the needs of current View Functions will exist.
Registering a handler only says how to create a Signal Graph node when and if it is needed.
Syntactic Sugar¶
The Layer 3 (materialized view) subscription above can be rewritten using some syntactic sugar:
(reg-sub
:id
;; input signals
:<- [:a] ;; means (subscribe [:a] is an input)
:<- [:b 2] ;; means (subscribe [:b 2] is an input)
;; computation function
(fn [[a b] query-v]
(calculate-it a b)))